
Recently, I had to quickly learn how to debug excessive spilling to disk on a Postgres instance. Information online on this topic is mostly scattered. I have a feeling that, whenever query plan analysis is involved, things always get a bit mystical.
Since I’m going to forget it all tomorrow, it’s good to write it down, both for others and for the future me.
Situation
You notice that your RDS instance is consistently eating large amounts of storage space (in my case, the rate was ~280MB/min).
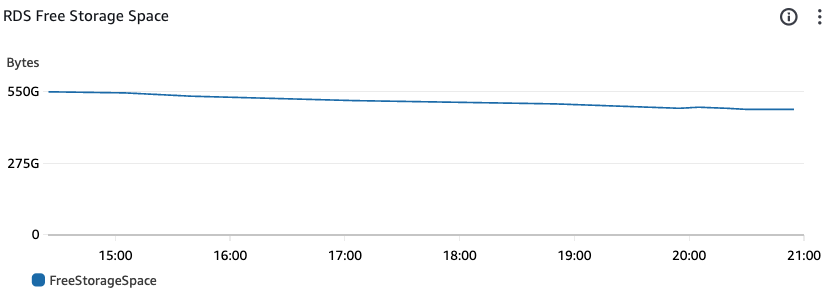
You ruled out the data itself, index bloating, checked that autovacuum is working. You also don’t have any long-running transactions.
You ruled out the WAL (Write-Ahead Logs). It’s easy to see whether it’s a problem in RDS monitoring by checking the TransactionLogsDiskUsage metric.
You also possibly notice that there is enough available memory, yet it’s not being used. So that can’t be spilling, right? Well… we’ll come back to that a bit later.
You can actually prove that crazy volumes are taken by temporary files:
SELECT temp_bytes FROM pg_stat_database;
Keep in mind that it’s a cumulative metric, it shows how many bytes have been written since the last reset. This looks pretty bad:
"temp_bytes": 275091742956
Now you know that temporary files are steadily eating your storage and threatening to kill your DB.
What can you do?
Don’t panic
Enable logging of temp file creation, and you will be able to see the exact queries writing to temporary files.
PostgreSQL has a setting for that: log_temp_files, where you can specify the file size threshold (in KB) for logging.
You can adjust settings globally through AWS, and the changes will apply immediately, no reboot needed. To do that, go to RDS Parameter groups.
Where are the logs?
Go to RDS -> DB Instances, chose yours, go to Logs & Events.
In the logs, you can now find entries like this:
STATEMENT: INSERT INTO foobar (id, name) SELECT * FROM UNNEST($1, $2) AS t(id, name) ORDER BY id ...
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp1234.5", size 124718640
If you’ve run out of storage, you’ll see spilling in the logs even without enabling any settings, since the errors are quite descriptive of the situation (always look for positives):
STATEMENT: INSERT INTO foobar (id, name) SELECT * FROM UNNEST($1, $2) AS t(id, name) ORDER BY id ...
ERROR: could not write to file "base/pgsql_tmp/pgsql_tmp1234.5": No space left on device
Now you know which query is causing the problem.
What now?
Memory
Remember when I mentioned memory earlier?
It turns out it’s not enough to just have gigabytes of available memory. You should also check what your work_mem value is.
You can either see it again in the RDS parameter group or simply run show work_mem;. The default value is 4MB.
This value defines how much memory can be used by a single node in your query execution. For example, if you’re doing sorting and the intermediate data doesn’t fit in memory, it’s written to a temporary file.
From Postgres documentation:
work_mem (integer)
Sets the base maximum amount of memory to be used by a query operation (such as a sort or hash table) before writing to temporary disk files. If this value is specified without units, it is taken as kilobytes. The default value is four megabytes (4MB). Note that a complex query might perform several sort and hash operations at the same time, with each operation generally being allowed to use as much memory as this value specifies before it starts to write data into temporary files. Also, several running sessions could be doing such operations concurrently. Therefore, the total memory used could be many times the value of work_mem; it is necessary to keep this fact in mind when choosing the value. Sort operations are used for ORDER BY, DISTINCT, and merge joins. Hash tables are used in hash joins, hash-based aggregation, memoize nodes and hash-based processing of IN subqueries.
To summarize: having a lot of available memory doesn’t mean it will be used; if intermediate data doesn’t fit in work_mem, it still spills to disk. Adjust this value carefully. If it’s set too high, you’re allowing each node in a query to use that much memory. If you run out of memory, things can go from bad to worse.
But what’s wrong with my query?
If you have some really complex queries, it’s not obvious which operation needs so much space. And if you want to optimize it, how do you even know what to fix?
You tried running EXPLAIN (ANALYZE, BUFFERS) ... with some test parameters, but nothing in the plan mentions writing to disk.
It seems you need some real execution plans, with real parameters, from real queries.
Here are some interesting settings:
shared_preload_libraries - make sure it contains auto_explain, which allows to log query plans of real queries at runtime.
Then, enable these:
auto_explain.log_analyze=1
auto_explain.log_buffers=1
Also, you can set the minimum duration for queries to be logged:
auto_explain.log_min_duration=1
Now, you’ll be able to see the execution plans of real queries in the logs. What should you look for?
🔸any mentions of Disk:
Sometimes it’s straightforward, for example:
-> Sort (cost=256783.74..258210.97 rows=570890 width=108) (actual time=124156.238..124157.932 rows=8198 loops=1)
Sort Key: a.some_value
Sort Method: external merge Disk: 152352kB
Buffers: shared hit=117500 read=38719, temp read=46571 written=65161
I/O Timings: shared read=3578.004, temp read=10198.270 write=19054.568
This means that sorting didn’t fit in memory and had to write about 150MB to disk.
🔸 any mentions of Buffers: temp written=n or Buffers: temp read=m written=n
Some info on it.
n is the value that you’re interested in, it specifies how many blocks of 8KB are written to disk.
Example:
-> Hash (cost=84674.80..84674.80 rows=1585280 width=58) (actual time=32708.031..32708.031 rows=1634942 loops=1)
Buckets: 131072 Batches: 32 Memory Usage: 5583kB
Buffers: shared hit=30103 read=38719, temp written=15455
I/O Timings: shared read=3578.004, temp write=5954.796
-> Seq Scan on abcdef a (cost=0.00..84674.80 rows=1585280 width=58) (actual time=42.932..18984.238 rows=1634942 loops=1)
Filter: (something IS NOT NULL)
Buffers: shared hit=30103 read=38719
I/O Timings: shared read=3578.004
Here, hash table was written to disk, 15455 * 8KB = ~120MB
Keep in mind that you should carefully check the most nested child nodes containing temp written, because parent nodes
have a value that’s the sum of their children’s values. Often, it all boils down to a single nested node, and that’s where you’ll find the real cause.
Sometimes, you simply have CTE scans:
-> CTE Scan on something (cost=0.00..0.04 rows=2 width=64) (actual time=0.002..930.622 rows=18607 loops=1)
Buffers: shared hit=111639, temp written=295
I/O Timings: temp write=18.274
This hints that the CTE (WITH cte as (...)) has been materialized, which Postgres can do behind the scenes when CTE is reused in the query. The materialized CTE is normally held in memory if it fits; otherwise, it spills to disk.
Now that you know what’s “wrong” with your queries, you can consider some ways to rewrite them.
Don’t forget to disable query plan logging afterward; it consumes a lot of, well, storage 😛
Cleaning up
Here’s another interesting piece of information that might be relevant.
Postgres also has this boolean setting: remove_temp_files_after_crash.
By default, it’s enabled, but if it’s disabled in your system, it means that if a backend crashes, Postgres won’t clean up the related temporary files so you can use them for debugging. However, if crashes happen a lot, you will accumulate these files and fill your storage.
Here are related docs.
In normal situation, Postgres cleans up temporary files, and you don’t need to do anything manually. It can happen though, that Postgres can’t keep up with the rate of writing, hence the storage space keeps shrinking.
Other
There’s a config that you can use to prohibit writing to temp files if the current process’s files
reach certain size threshold (in KB): temp_file_limit. You’ll be getting errors on such attempts.
Related documentation.
Cheat sheet
work_memspecifies how much memory you allow each node to uselog_temp_filesboolean to enable logging queries that write temporary files to diskremove_temp_files_after_crashboolean to let PG remove temp files in case of crashestemp_file_limitthreshold in KB when temp files start getting rejected,-1== unlimited- logging query plans at runtime:
shared_preload_librariesshould containauto_explainauto_explain.log_analyze=1(enabled)auto_explain.log_buffers=1(enabled)auto_explain.log_min_duration=<any_duration>
- look for these patterns in query plans to identify writing to temp files (where
nis number of8KBblocks):Disk:Buffers: temp written=nBuffers: temp read=m written=n
- examples of operations that could be writing to temp files:
- hash
- sort
- CTE scan
Hope this helps! Good luck!
